作成 2014年12月12日
”socket.io”を利用し、HTTP通信のようにブラウジングできるシステム形態の実現。
”socket.io”などのWebSocket通信と言えば、リアルタイムの双方向通信ができるの技術。このWebSocket通信技術によって、今まで簡単にできなかった大規模なサーバープッシュ通信などのWeb環境を提供し始めている。その一方で、WebSocket通信技術学習の第一歩がチャットアプリであることから、普通のチャットとの相違が分かり難い人も多いのでは。
ここでは、”socket.io”の通信フレームワークを利用した非同期のアプリケーション連携について、その実装を試みる。
何をするか
HTTPサーバーとのやり取りでは、ブラウザーからのリクエストに対して、サーバーがリクエストに合った結果を、ブラウザーにレスポンスとして返す。ブラウザーはサーバーの動きに同期しているため、設定されているタイムアウトまで、ずーと待っている。Webシステムは同期を前提に成り立っているため、Webサービスを中心としたアプリケーション連携が簡単に実装できる。
”socket.io”を利用してHTTP通信みたいなことができないかと思っている中で、nkzawaさんの”socket.io java client”(https://github.com/nkzawa/socket.io-client.java)の記事を見て、何とか上記のサービスが実現できるのではないか、と考えた。手軽に”socket.io”を利用するにはnode.jsが最適である。しかしながらnode.jsは良い点もあれば、弱点もある。ここでは、node.jsが得意とするところ、Javaが得意とするところを利用したシステム形態を検討する。
node.jsのsocket.ioサーバーとsocket.ioのJavaアプリを組み合わせ(child_processを使わず)、ブラウザーから送られてきたファイルをJavaアプリで処理し、その結果をsocket.io通信でブラウザーに返すことを実装する。
システム構成
システムは、ブラウザー、node.jsのサーバー、Javaのクライアントからなる。
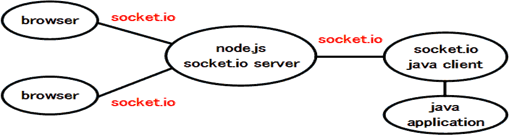
実装したシステムについて
実装したシステムは次の通りで、ブラウザーからサーバーを経由しJavaクライアントで処理を行い、リクエスト結果がブラウザーに戻る。システムは双方向通信をベースとするため、それぞれの役割の中にデータの送受信を伴うものとなっている。システムを構成する全てのプログラム及びサンプルデータはここからダウンロードできる。(ng.zip)
デモ(http://www.osaka3t.com:4000/)※プロキシー経由できない
使い方
node serv.js 4000
java SocketClient 4000 ngwordfile
ブラウザーでhttp://127.0.0.1:4000
テスト環境
OS
Windows8.1
nodeサーバー
node "v0.11.11"
socket.io.js "1.2.1"
などのモジュール
Java
java version "1.7.0_15"
Jarファイル
socket.io-client-0.3.0.jar
engine.io-client-0.3.1.jar
org.json-20120521.jar
Java-WebSocket-1.3.0.jar
commons-codec-1.10.jar
juniversalchardet-1.0.3.jar
----------------------------------------------------
ブラウザーのHTML
<div ondragover="onDragOver(event)">//ファイルのドロップアクションを受け付ける
var reader = new FileReader();//関数onDragOverで、FileAPIでファイルを読み込む
reader.onload = function (evt) {
var data = {};
data.file = evt.target.result;//base64形式のファイル内容
data.ftype = f.type;
socket.emit("upload", data);//サーバーへの送信
}
socket.on("upload_result", function(data){//サーバーからデータ受信と結果表示
var nd=document.getElementById("msg_list");
nd.innerHTML='<div style="font-size:14px;">'+data.data+'</div>';
});
----------------------------------------------------
socket.ioサーバー
socket.on("upload", function(data){//ブラウザーからのデータ受信
var ty="data:"+data.ftype+";base64,";//ファイルはbase64でエンコードされている
var dd=data.file.substring(ty.length);//エンコードヘッダーの削除
if(nicknames["java_NG"]){//Javaクライアントへのデータ送信(java_NGはニックネーム)
io.to(nicknames["java_NG"]).json.emit("NG", {data:dd, sid:socket.id, ftype:data.ftype});
}
});
socket.on("NG_result", function(data){//Javaクライアントから結果受信
io.to(data.sid).json.emit("upload_result", {data:data.data});//sidで特定のブラウザーに結果送信
});
----------------------------------------------------
socket.io Javaクライアント
socket.on("NG", new Emitter.Listener() {//サーバーからのデータ受信
@Override
public void call(Object... args) {
JSONObject json = (JSONObject)args[0];
try {
String sid=json.getString("sid");//リクエストをした者のsocket.io
String dd=json.getString("data");//base64形式
String content = ng.textConvert( Base64.decodeBase64( dd.getBytes( ) ) ) ;
String[ ] ss = content.split( crlf ) ;
String s = "" ;
for ( int i = 0; i < ss.length; i++ ) {//NGワードのマッチング処理
String line = tb.convert( ss[ i ], false ) ;
tm.match( line ) ;
s += ng.toHigtLight( ss[ i ], tm.getData( ) ) ;//NGワードのハイライト処理
}
json = new JSONObject();
json.put("sid", sid);
json.put("data", s);
socket.emit("NG_result", json);//処理結果をサーバーへ送信
} catch( JSONException e ) {}
}
});
JavaによるNGワード・マッチング
Javaクライアントの処理として、NGワード・マッチングを実装した。NGワードは、ニコニコ生放送:運営NGワード一覧(http://dic.nicovideo.jp/a/%E3%83%8B%E3%82%B3%E3%83%8B%E3%82%B3%E7%94%9F%E6%94%BE%E9%80%81%3A%E9%81%8B%E5%96%B6ng%E3%83%AF%E3%83%BC%E3%83%89%E4%B8%80%E8%A6%A7)などを利用し、その他収集したNGワードを付加した。
NGワード・マッチングの方法は、”大量のマッチ対象文字列がある場合の文字列検索処理”(http://d.hatena.ne.jp/ux00ff/20110612/1307886259)を利用した。この方法はトライ木(英字だけでなく、日本語にも対応)を用いたマッチング技術で、大変高速である。オリジナルのプログラムTreeMatcherをベースに最長一致法によるマッチングプログラムにアレンジした。
マッチングスピードの計測
テストデータは、マッチング辞書からランダムに抽出した1行150文字越えとし10,000行を作成した。パフォーマンスの計測は、データの受送信、トライ木の作成のコスト(日本語ワード775語で約15msec)は含まれず、マッチング処理(結果を標準出力にはきだす時間を含む)を計測した。処理は大変高速であった。TwitterなどのマイクロブログのNGワード検出を考えると、1ツィート当たり約0.35msec(i5-3337U CPU, 1.8GHz)で実施できることが分かった。
英字ワード77語(平均4.97文字)の辞書
2515.5msec(10回)
日本語ワード775語(平均3.32文字、英数112語を含む)
3509.5msec(10回)
結果
node.jsとJavaアプリケーションは、nkzawaさんの”socket.io java client”によってシームレスに連携することができた。
nkzawaさんからアドバイスを頂き、ありがとうございました。
/*
大量のマッチ対象文字列がある場合の文字列検索処理
http://d.hatena.ne.jp/ux00ff/20110612/1307886259
Arranged by T. Osaka (2014/11/7)
使い方
javac -encoding UTF-8 TreeMatcher.java
java TreeMatcher
*/
import java.io.File ;
import java.io.FileReader ;
import java.io.FileInputStream ;
import java.io.InputStreamReader ;
import java.io.BufferedReader ;
import java.io.FileNotFoundException ;
import java.io.IOException ;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.HashMap ;
import java.util.Map ;
import java.util.ArrayList ;
import org.mozilla.universalchardet.UniversalDetector ;
/**
* マッチ対象の文字列集合を前処理し、ツリー構造で保持する。
* NGワードチェックなど、マッチ対象の文字列集合がほぼ静的に決定されるケースで高速に動作する。
*/
public class TreeMatcher {
static private UniversalDetector detector = null ;
static private String crlf = null ;
public static void main( String[ ] args ) throws Exception {
String str = "ツッチー,つっちー,土田,土田晃,土田晃之助,エロ,エロい,ヤマちゃん,やまちゃん,山ちゃん,山里,えいこう,つくだ,南キャン山,南キャン山里,南キャン山田" ;
String[ ] s = str.split( "," ) ;
TreeMatcher tm = new TreeMatcher( s ) ;
String data = "「山里かい,信用できないよ!、土田は土田晃なんだ たぶん黒だよ」えいこうちゃんやまちゃんつくだ一番信用された南キャン山里つっちーがいなかったと人が言うことかw南キャン山" ;
System.out.println( data ) ;
tm.match( data ) ;
tm.disp( );
}
// -------------------------------------------------------------------------
private CharTreeNode rootNode = null ; //トライ木構造のデータ
private ArrayList<WordData> array = null ; //結果をWordDtataで記録
public TreeMatcher( String[ ] words ) {
rootNode = new CharTreeNode( null ) ;
rootNode.addWords( words ) ;
}
public TreeMatcher( ArrayList<String> w ) {
rootNode = new CharTreeNode( null ) ;
String[ ] words = new String[ w.size( ) ] ;
for ( int i = 0; i < w.size( ); i++ ) words[ i ] = (String)w.get( i ) ;
rootNode.addWords( words ) ;
}
public TreeMatcher( String fname ) {
ArrayList<String> w = fileRead( fname ) ;
rootNode = new CharTreeNode( null ) ;
String[ ] words = new String[ w.size( ) ] ;
for ( int i = 0; i < w.size( ); i++ ) words[ i ] = (String)w.get( i ) ;
rootNode.addWords( words ) ;
}
public CharTreeNode getTreeNode( ) { return rootNode ; }
public void setTreeNode ( CharTreeNode rootNode ) { this.rootNode = rootNode ; }
public void makeTreeNode( String[ ] words ) {
rootNode = new CharTreeNode( null ) ;
rootNode.addWords( words ) ;
}
public ArrayList getData( ) { return array ; }
public void disp( ) {
for ( int i = 0; i < array.size( ); i++ ){
WordData t = (WordData)array.get( i ) ;
System.out.println( t.getPosition( ) + " " + t.getWord( ) ) ;
}
}
private ArrayList<String> fileRead( String filePath ) {
ArrayList<String> al = new ArrayList<String>( ) ;
BufferedReader in = null ;
try {
File file = new File( filePath ) ;
in = new BufferedReader( new InputStreamReader( new FileInputStream( file ), "UTF-8" ) ) ;
String line ;
while ( ( line = in.readLine( ) ) != null ) {
if ( line.startsWith( "#" ) ) continue ;
//System.out.println( line ) ;
al.add( line ) ;
}
} catch ( FileNotFoundException e ) {
e.printStackTrace( ) ;
} catch ( IOException e ) {
e.printStackTrace( ) ;
} finally {
try {
in.close( ) ;
} catch ( IOException e ) {
e.printStackTrace( ) ;
}
}
return al ;
}
//ファイルがbase64の時base64デコードを、その他の時バイナリでファイルを読む
private String[ ] fileRead( File inf ) {
String crlf = System.getProperty( "line.separator" ) ;
String[ ] ss = null ;
try {
FileInputStream fi = new FileInputStream( inf ) ;
byte[ ] indata = new byte[ (int)inf.length( ) ] ;
fi.read( indata ) ;
fi.close( ) ;
String content = textConvert( indata ) ;
ss = content.split( crlf ) ;
} catch ( Exception e ) {
e.printStackTrace( ) ;
}
return ss ;
}
//バイナリ列のエンコードを調べ、そのエンコードでバイナリ列を読み直し、テキストを得る
public String textConvert( byte[ ] outdata ) {
String content = null ;
try {
// 読み込んだバイト列を juniversalchardet へ渡す
detector.handleData( outdata, 0, outdata.length ) ;
detector.dataEnd( ) ;
//文字コードの判定
String encoding = detector.getDetectedCharset( ) ;
//System.out.println( "encoding:" + encoding ) ; //文字コード判定結果の表示
detector.reset( ) ;
// コンテンツを String型にする(この時点で UTF-8 に変換されている)
content = new String( outdata, encoding ) ;
} catch ( Exception e ) {
e.printStackTrace( ) ;
}
return content ;
}
// -------------------------------------------------------------------------
/**
* マッチ処理を行う。
*/
public void match( String target ) {
//System.out.println( target +"<br>" ) ;
array = new ArrayList<WordData>( ) ;
CharTreeNode currentNode = null ;
int num = target.length( ) ;
for ( int i = 0; i < num; i++ ) {
String s = "" ;
currentNode = rootNode ;
for ( int k = 0; i + k < num; k++ ) {
Character c = target.charAt( i + k ) ;
currentNode = currentNode.child.get( c ) ;
s += c ;
if ( currentNode == null ) {
break ;
}
//System.out.println( i + " " + k + " " + c + ":" + s + ">" + currentNode.child.size( ) + " " + currentNode.end ) ;
if( currentNode.end ) { //トライ木の終端
if ( currentNode.child.size( ) == 0 ) { //トライ木に枝がない場合
array.add( new WordData( i, s ) );
i += k ;
}
else if ( ( i + k ) == ( num - 1 ) ) { //行末の場合
array.add( new WordData( i, s ) ) ;
break ;
}
else { // 最長一致でのマッチングを行う
if ( ( i + k + 1 ) < num ) {
c = target.charAt( i + k + 1 ) ;
CharTreeNode ch = currentNode.child.get( c ) ;
if ( ch == null ) { //次の文字が候補にない場合
array.add( new WordData( i, s ) ) ;
i += k ;
break ;
}
else if ( ( ch.end ) ) { //トライ木の終端
array.add( new WordData( i, s + c ) ) ;
i += k + 1 ;
break ;
}
else {
if ( ( i + k + 2 ) < num ) {
c = target.charAt( i + k + 2 ) ;
//System.out.println( "c=" + c + " " + ch.child.get( c ) + " " + ch.end ) ;
if ( ch.child.get( c ) == null ) { //次の文字が候補にない場合
array.add( new WordData( i, s ) ) ;
i += k - 1 ;
break ;
}
}
}
}
}
}
}
}
}
}
/**
* ツリー構造を保持するクラス。
*
*/
class CharTreeNode {
boolean end = false ;
Character value ;
Map<Character, CharTreeNode> child = new HashMap<Character, CharTreeNode>( ) ;
CharTreeNode( Character value ) {
this.value = value ;
}
public void addWords( String[ ] words ) {
for ( String word : words ) {
addWord( word ) ;
}
}
private void addWord( String word ) {
addWord( word, this ) ;
}
private void addWord( String value, CharTreeNode parent ) {
//System.out.println( value + "." ) ;
if ( value == null || value.length( ) == 0 ) {
parent.end = true ;
return ;
}
Character firstLetter = value.charAt( 0 ) ;
CharTreeNode current = null ;
if ( parent.child.containsKey( firstLetter ) ) {
current = parent.child.get( firstLetter ) ;
} else {
current = new CharTreeNode( firstLetter ) ;
parent.child.put( firstLetter, current ) ;
}
current.addWord( value.substring( 1, value.length( ) ) ) ;
}
}
class WordData {
int pos ; //出現位置
String word ; //出現したword
WordData( int pos, String word ) {
this.pos = pos ;
this.word = word ;
}
public int getPosition( ) { return pos ; }
public String getWord( ) { return word ; }
}
(記 大坂 哲司)